We’ve rolled out some exciting updates for DEPA‑Training, making it easier to rapidly prototype and run diverse training scenarios — complete with electronic contracts, confidential cleanrooms, privacy-preservation and configurable training SDKs.
✨ What’s new
👉 GUI for end-to-end execution
👉 Step-by-step guide to create and run your own training scenarios
👉 New scenarios introduced for complex multi-party training: MRI brain tumor segmentation, credit default risk prediction
Before we dive in, let’s quickly recall what the Data Empowerment and Protection Architecture (DEPA) really is.
What is DEPA and why does it matter?
India Stack is evolving at population scale, enabling the flow of people (Aadhaar, eKYC, DigiLocker, DigiYatra, etc), money (UPI, OCEN), and information (DEPA and Account Aggregator) through Digital Public Infrastructure (DPI). DEPA is critical in this third layer as it enables the responsible flow of data between individuals and organisations for more complex tasks such as AI model training, AI inference and analytics.
As the name suggests, DEPA rests on two key elements. The first is protection, founded on the bedrock of privacy, consent, accountability and purpose limitation of data. The second is empowerment, democratizing data access and enabling the ecosystem to responsibly innovate with it, whether for training AI models, personalizing products and services, advancing scientific research, and a lot more.
In light of emerging data protection laws such as the DPDP, GDPR, and others, there is a need for a framework that enables the responsible use of data — unlocking its value while ensuring regulatory compliance and serving the broader public interest.
Ultimately, DEPA solves for two core challenges at the heart of data sharing — Trust and Flow — keeping the rest open and flexible for innovation.
What is DEPA‑Training?
The vision behind DEPA for Training (aka DEPA‑Training) is simple: For India to not only be a consumer of AI, but also a producer of AI, and in a responsible and democratized manner.
AI’s first big leap came from public data. That well is running dry. Our belief is that for the next wave of AI innovation — smarter AI for healthcare, personalized finance, scientific discovery and more — proprietary data will be crucial. But today, that data is fragmented, locked in silos, and difficult to use — often running into challenges around privacy, compliance, and regulatory constraints.
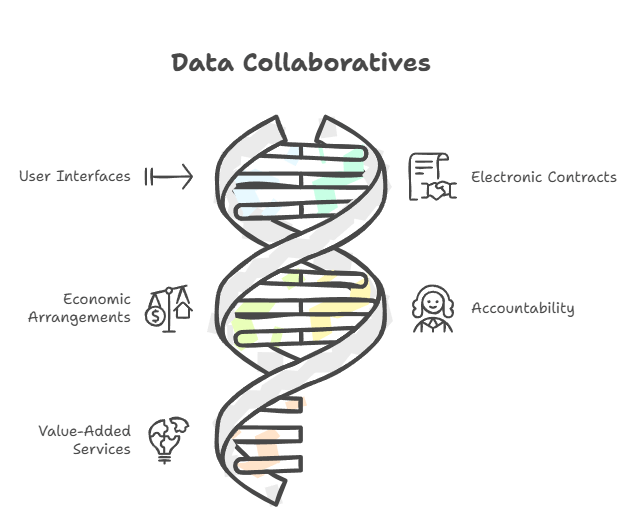
Enter DEPA-Training — a techno-legal Digital Public Infrastructure (DPI) designed to enable secure, agile, and scalable AI model training on sensitive data. It does so by assembling a set of frontier technological primitives:
- Confidential Clean Rooms (CCRs): Isolated compute environments that can cryptographically attest to their integrity, where data can be processed securely without external exposure.
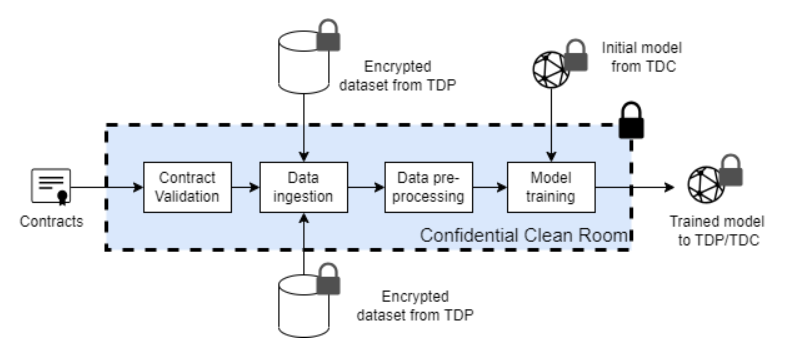
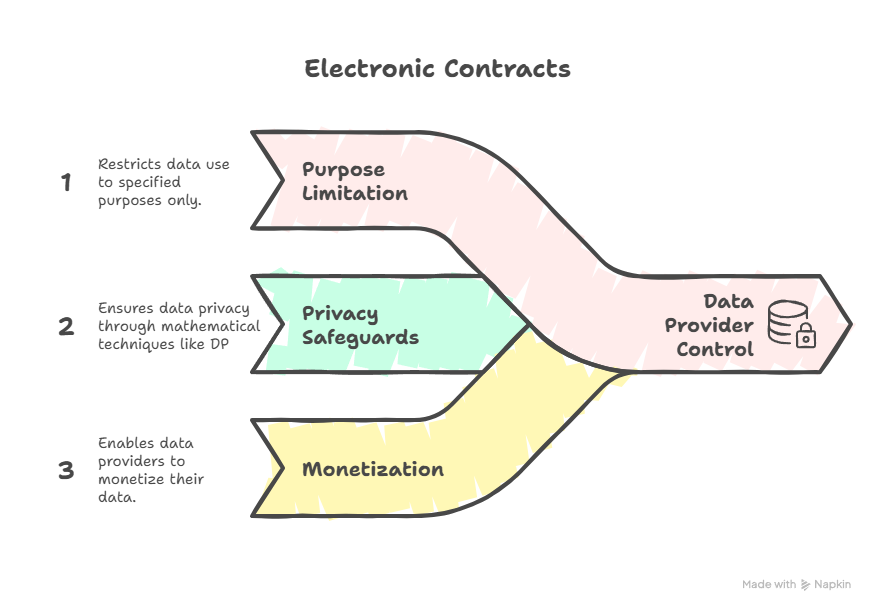
- Electronic Contracts: Code-enforced legal agreements between transacting parties, that give data providers control over how their data is used, for eg. through purpose limitation, privacy safeguards and monetization.
- Secure Training Sandbox: Modular and configurable sandboxes and SDKs for building privacy-preserving and compliant training pipelines across diverse model architectures and data types.
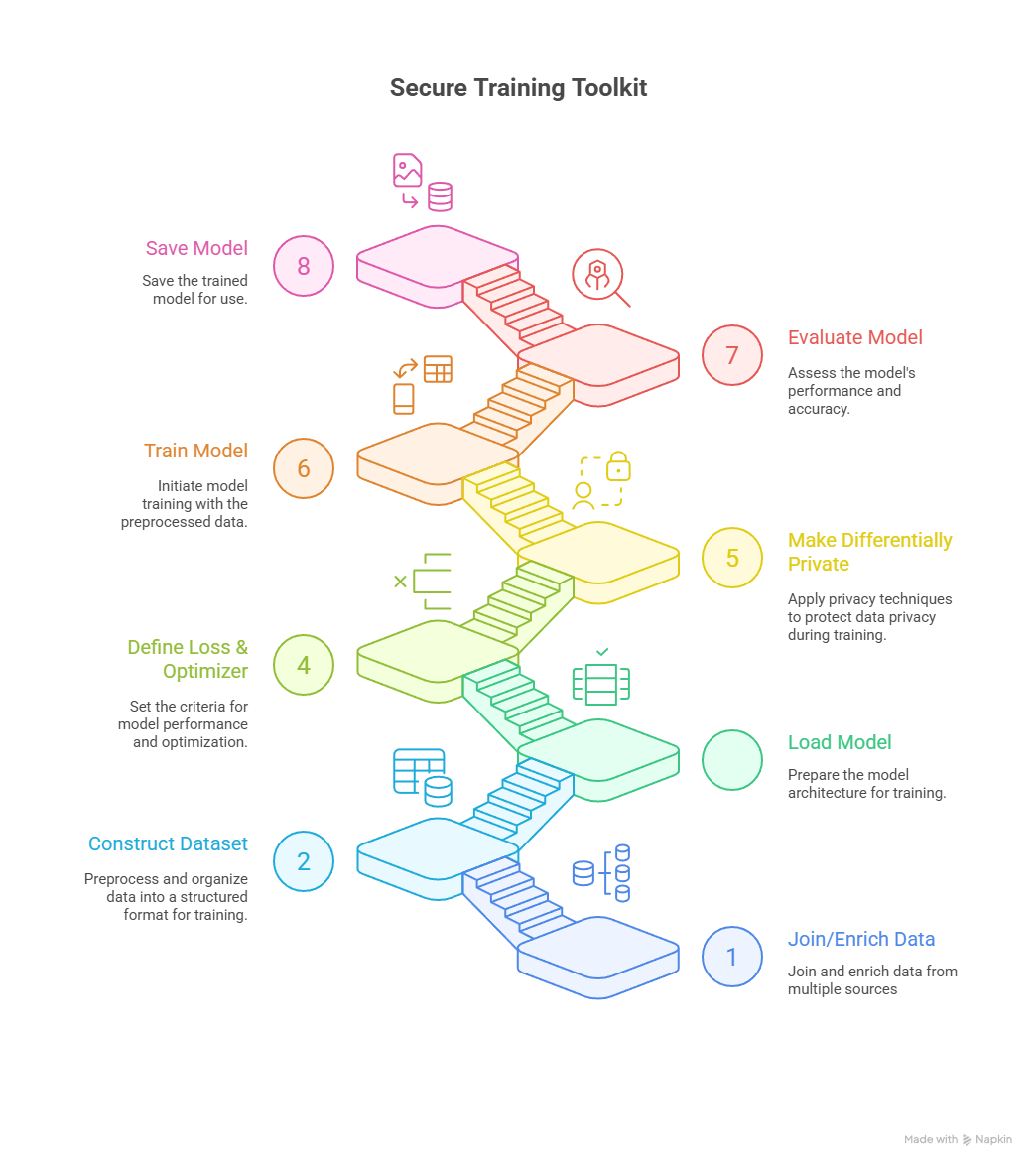
What’s new in DEPA-Training?
Graphical user interface
We’ve introduced an interactive GUI that enables users to explore, configure, and execute DEPA-Training scenarios end to end. The application automatically discovers available scenarios in the repository and provides an intuitive interface to run them — eliminating the need for command-line interaction. A similar GUI workflow is also provided for contract signing.
Scenarios you can try out today
To bring DEPA-Training to life, we showcase a diverse set of scenarios that demonstrate what’s possible in practice. These examples illustrate pathways toward solving larger global challenges and span multiple data modalities (e.g., tabular, images), model paradigms (e.g., classical ML, MLPs, CNNs), and prediction tasks (e.g., regression, classification, image segmentation).
Disease Surveillance Modeling
Pandemics don’t wait. Timely, accurate data can save millions of lives. Yet most infection data is scattered, siloed, and too sensitive to share. With differential privacy, institutions can securely pool data to track virus spread, map risk patterns, and test interventions — powering real-time, data-driven epidemic response.
Example: COVID-19 scenario
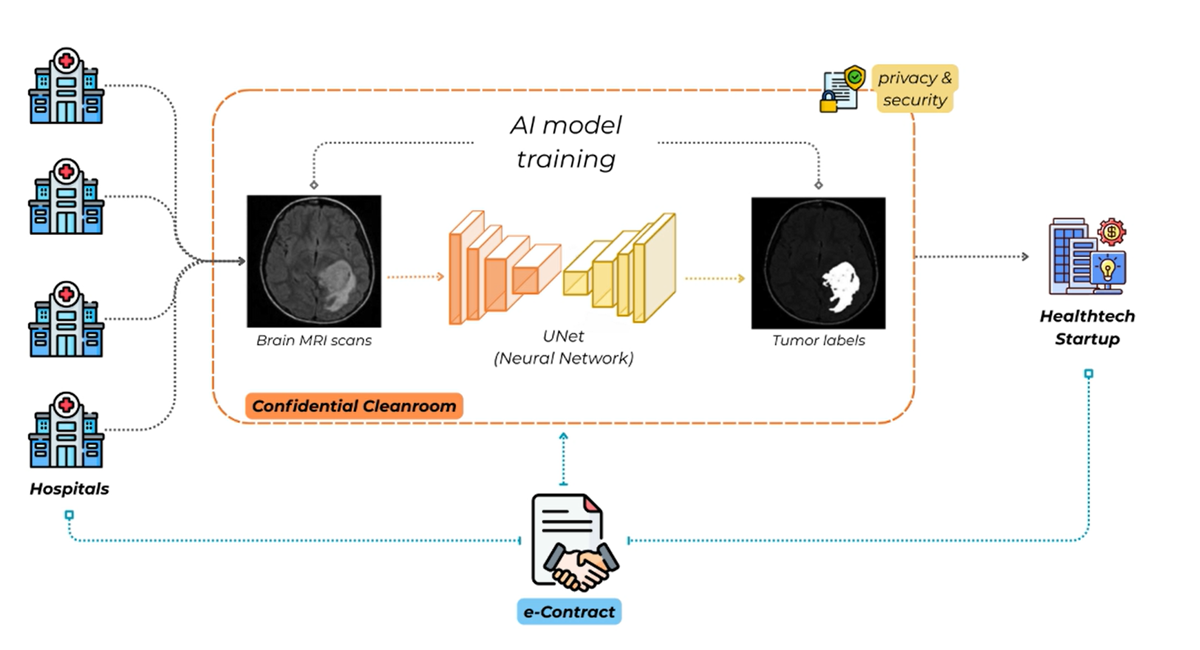
Medical Image Modeling
From cancer to cardiovascular disease, from neurology to rare disorders — modern medicine increasingly depends on imaging. Yet medical images are among the hardest datasets to share, trapped in hospital silos and governed by strict privacy laws. DEPA makes it possible to combine imaging data across borders and institutions, unlocking AI models that are more accurate, generalizable, and equitable. This accelerates breakthroughs in diagnostics, improves treatment planning, and addresses one of healthcare’s biggest global challenges: scaling precision medicine while safeguarding patient trust.
Example: BraTS scenario
Financial Credit Risk Modeling
Access to fair credit fuels economic growth, but risk assessment is often limited by partial data. By safely combining insights across financial institutions, DEPA enables more accurate credit scoring, reduces defaults, and strengthens financial stability — empowering individuals and businesses alike with better access to capital.
Example: Credit Risk scenario
Build your own Scenarios
A new step-by-step guide walks you through building and running your own DEPA-Training scenarios — making it easy to rapidly prototype and iterate with training use-cases of your own.
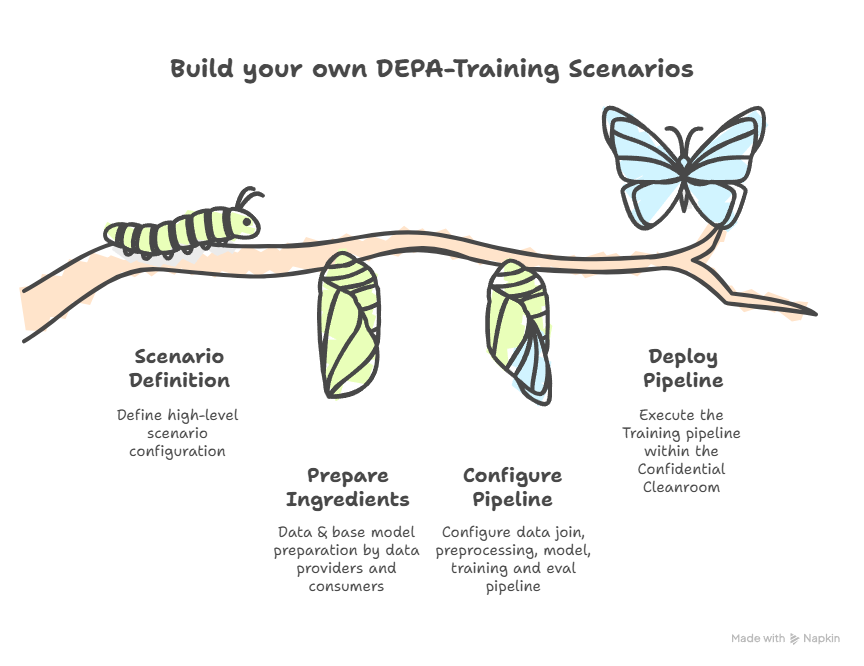
Currently, DEPA-Training supports the following training frameworks, libraries and file formats (more will be included soon):
- Frameworks: PyTorch, Scikit‑Learn, XGBoost (LLM Finetuning to be added soon!)
- Libraries: Opacus, PySpark, Pandas (HuggingFace support coming soon!)
- Formats: ONNX, Safetensors, Parquet, CSV, HDF5, PNG (No pickle-based formats for security reasons)
What’s in it for the ecosystem?
DEPA-Training democratizes responsible data sharing and model training for all!
- Enterprises & Startups → Unlock the value of private data to build smarter products and services, while remaining compliant to data laws. Collaborate across organizations to create solutions that no single dataset could power.
- Research Institutions → Pool data at scale to tackle grand challenges, drive scientific discovery, and advance knowledge for the public good.
- Policy & Legal Experts → Shape the future of data governance by operationalizing privacy, consent, purpose limitation, and accountability in practice.
- Builders & researchers → Join us in co-creating this framework!
Get started
👉 Get your hands dirty: DEPA‑Training on GitHub 🛠️
👉 Explore the documentation: DEPA.World 📜
👉 Watch the Open Houses: YouTube Playlist 🎬
👉 Think big: What challenges has data privacy kept off-limits? What data has felt forever inaccessible? With DEPA-Training, those doors may finally open. 💡
Interested in contributing to DEPA? Join our group of no-greed no-glory volunteers! Apply here
Please note: The blog post is authored by our volunteers, Sarang Galada, Dr. Shyam Sundaram, Kapil Vaswani and Pavan kumar Adukuri