This is the 4th blog in a series of blogs describing and signifying the importance of DPI for AI, a privacy-preserving techno-legal framework for AI data collaboration. Readers are encouraged to first go over the earlier blogs for better understanding and continuity.
We are at the cusp of history with regard to how AI advancements are unfolding and the potential to build a man-machine society of the future economically, socially, and politically. There is a great opportunity to understand and deliver on potentially breakthrough business and societal use cases while developing and advancing foundational capabilities that can adapt to new ideas and challenges in the future. The major startups in Silicon Valley and big techs are focused first on bringing the advancements of AI to first-world problems – optimized and trained for their contexts. However, we know that first world’s solutions may not work in diverse and unstructured contexts in the rest of the world – may not even for all sections of the developed world.
Let’s address the elephant in the room – what are the critical ingredients that an AI ecosystem needs to succeed – Data, enabling regulatory framework, talent, computing, capital, and a large market. In this open house
we make a case that India is the place that excels in all these dimensions, making it literally a no-brainer whether you are an investor, a researcher, an AI startup, or a product company to come and do it in India for your own success.
India has one of the most vibrant, diverse, and eager markets in the world, making it a treasure chest of diverse data at scale, which is vital for AI models. While much of this data happens to be proprietary, the DPI for AI data collaboration framework makes it available in an easy and privacy-preserving way to innovators in India. Literally, no other country has such a scale and game plan for training data. One may ask that diversity and scale are indeed India’s strengths but where is the data? Isn’t most of our data with the US-based platforms? In this context, there are three types of Data:
a. Public Data,
b. Non-Personal Data (NPD), and
c. Proprietary Datasets.
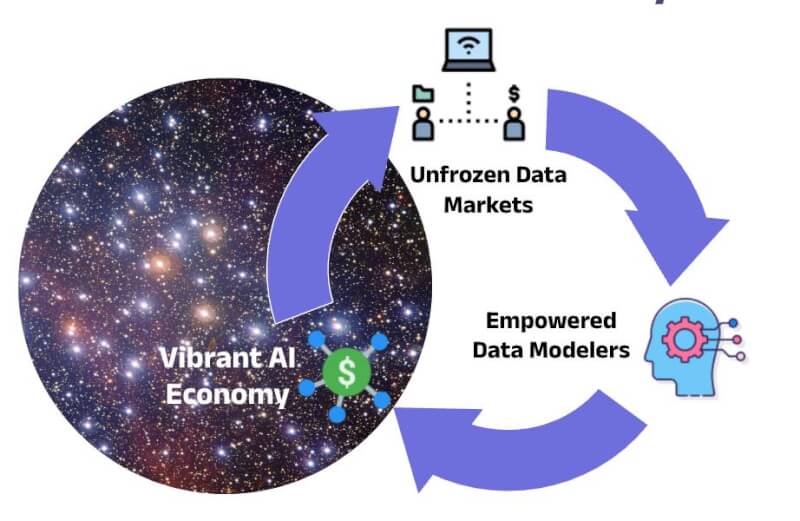
Let’s look at health. India has far more proprietary datasets than the US. It is just frozen in the current setup. Unfreezing this will give us a play in AI. This is exactly what DPI for AI is doing – in a privacy-preserving manner. In the US, health data platforms like those of Apple and Google are entering into agreements with big hospital chains – to supplement their user health data that comes from wearables. How do we better that? This is the US Big Tech-oriented approach – not exactly an ecosystem approach. Democratic unfreezing of health data with hospitals is the key today. DPI for AI would do that even for all – small or big, developers or researchers! We have continental-scale data with more diversity than any other nation. We need a unique way to unlock them to enable the entire ecosystem, not just big corporations. If we can do that, and we think we can via DPI for AI, we will have AI winners from India.
Combine this with India’s forward looking regulatory thought process that balances Regulation for AI and Regulation of AI in a unique way that encourages innovation without compromising on individual privacy and other potential harms of the technology. The diversity and scale of the Indian market act like a forcing function for innovators to think of robustness, safety, and efficiency from the very start which is critical for the innovations in AI to actually result in financial and societal benefits at scale. There are more engineers and scientists of Indian origin who are both creating AI models or developing innovative applications around AI models. Given our demographic dividend, this is one of our strengths for decades to come. Capital and Compute are clearly not our strong points, but capital literally follows the opportunity. Given India’s position of strength on data, regulation, market, and talent, capital is finding its way to India!
So, what are you all waiting for? India welcomes you with continental scale data with a lightweight but safe regulatory regime and talent like no place else to come build, invest, and innovate in India. India has done it in the past in various sectors, and it is strongly positioned to do it again in AI. Let’s do this together. We are just getting started, and, as always, are very eager for your feedback, suggestions, and participation in this journey!
Please share your feedback here
For more information, please visit depa.world
Please note: The blog post is authored by our volunteers, Sharad Sharma, Gaurav Aggarwal, Umakant Soni, and Sunu Engineer