iSPIRT works to transform India into a hub for new generation software products, by addressing crucial government policy, creating market catalysts and grow the maturity of product entrepreneurs. Welcome to the Official Insights!
In just a decade, India has redefined how nations can harness technology for the public good. Through Digital Public Infrastructure (DPI), such as Aadhaar, UPI, and Account Aggregator, followed by newer innovations like OCEN and ONDC, India has shown the world how open, interoperable, and inclusive digital systems when designed as privately provisioned, public infrastructure; can spark innovation, scale rapidly, and empower communities at the grassroots.
To capture these lessons and provide a practical guide for policymakers, technologists, and global stakeholders, iSPIRT Foundation has contributed to the development of the DPI Handbook: Foundations of Digital Public Infrastructure. This handbook distills a decade of India’s pioneering experience into actionable insights, frameworks, and design principles that can help other nations build their own inclusive and interoperable DPI. The paper is now published on the Research and Information System for Developing Countries (RIS)
This Handbook is not the product of a single author, but rather the culmination of years of dedicated volunteerism at iSPIRT, where technologists, policymakers, entrepreneurs, and thinkers came together to exchange ideas, build prototypes, and debate design choices. Each page reflects this collaborative spirit, proof that when diverse minds work in concert, they can create frameworks that transform entire societies.
We extend our deepest gratitude to the iSPIRT volunteer community, past and present, whose passion and commitment, have been instrumental in shaping India’s DPI journey. Their contributions embody the ethos of building digital public infrastructure as a shared national mission.
We hope the DPI Handbook becomes both a guide and an inspiration, for nations building their own digital public infrastructure, and for all who believe that technology, when designed for the public good, can change the course of societies.
Please note: The blog post is co-authored by our volunteer, Arun Iyer
iSPIRT would like to extend its gratitude to Shri. Rajeev Chawla – IAS, Strategic Advisor and Chief Knowledge Officer- Ministry of Agriculture & Farmer’s Welfare who co-authored this Handbook, for his insightful perspectives. We would also like to thank Shri. Sachin Chaturvedi, Director General – RIS for graciously writing the Preface to this Handbook
This is the 4th blog in a series of blogs describing and signifying the importance of DPI for AI, a privacy-preserving techno-legal framework for AI data collaboration. Readers are encouraged to first go over the earlier blogs for better understanding and continuity.
We are at the cusp of history with regard to how AI advancements are unfolding and the potential to build a man-machine society of the future economically, socially, and politically. There is a great opportunity to understand and deliver on potentially breakthrough business and societal use cases while developing and advancing foundational capabilities that can adapt to new ideas and challenges in the future. The major startups in Silicon Valley and big techs are focused first on bringing the advancements of AI to first-world problems – optimized and trained for their contexts. However, we know that first world’s solutions may not work in diverse and unstructured contexts in the rest of the world – may not even for all sections of the developed world.
Let’s address the elephant in the room – what are the critical ingredients that an AI ecosystem needs to succeed – Data, enabling regulatory framework, talent, computing, capital, and a large market. In this open house
we make a case that India is the place that excels in all these dimensions, making it literally a no-brainer whether you are an investor, a researcher, an AI startup, or a product company to come and do it in India for your own success.
India has one of the most vibrant, diverse, and eager markets in the world, making it a treasure chest of diverse data at scale, which is vital for AI models. While much of this data happens to be proprietary, the DPI for AI data collaboration framework makes it available in an easy and privacy-preserving way to innovators in India. Literally, no other country has such a scale and game plan for training data. One may ask that diversity and scale are indeed India’s strengths but where is the data? Isn’t most of our data with the US-based platforms? In this context, there are three types of Data:
a. Public Data, b. Non-Personal Data (NPD), and c. Proprietary Datasets.
Let’s look at health. India has far more proprietary datasets than the US. It is just frozen in the current setup. Unfreezing this will give us a play in AI. This is exactly what DPI for AI is doing – in a privacy-preserving manner. In the US, health data platforms like those of Apple and Google are entering into agreements with big hospital chains – to supplement their user health data that comes from wearables. How do we better that? This is the US Big Tech-oriented approach – not exactly an ecosystem approach. Democratic unfreezing of health data with hospitals is the key today. DPI for AI would do that even for all – small or big, developers or researchers! We have continental-scale data with more diversity than any other nation. We need a unique way to unlock them to enable the entire ecosystem, not just big corporations. If we can do that, and we think we can via DPI for AI, we will have AI winners from India.
Combine this with India’s forward looking regulatory thought process that balances Regulation for AI and Regulation of AI in a unique way that encourages innovation without compromising on individual privacy and other potential harms of the technology. The diversity and scale of the Indian market act like a forcing function for innovators to think of robustness, safety, and efficiency from the very start which is critical for the innovations in AI to actually result in financial and societal benefits at scale. There are more engineers and scientists of Indian origin who are both creating AI models or developing innovative applications around AI models. Given our demographic dividend, this is one of our strengths for decades to come. Capital and Compute are clearly not our strong points, but capital literally follows the opportunity. Given India’s position of strength on data, regulation, market, and talent, capital is finding its way to India!
So, what are you all waiting for? India welcomes you with continental scale data with a lightweight but safe regulatory regime and talent like no place else to come build, invest, and innovate in India. India has done it in the past in various sectors, and it is strongly positioned to do it again in AI. Let’s do this together. We are just getting started, and, as always, are very eager for your feedback, suggestions, and participation in this journey!
This is the third in a series of blogs describing the structure and importance of Digital Public Infrastructure for Artificial Intelligence (DPI for AI), a privacy-preserving techno-legal framework for data and AI model building collaborations. Readers are encouraged to go over the first and second blogs for better understanding and continuity.
The techno-legal framework of DEPA, elaborated upon in the earlier blogs, provides the foundations. From multiple discussions and history, it is clear that building and growing a vibrant AI economy that can create a product nation in India, requires a regulatory framework. This regulatory structure will serve as the legal partner to the technology aspect and work hand in hand with it. Upon this reliable techno-legal foundation will the ecosystem and global product companies from India be materialized.
‘Data Empowerment And Protection Architecture’ – or DEPA’s – worldview of ‘regulation for AI’, rather than the more conventional ‘Regulation of AI’ espoused by US, EU and so on sets DEPA apart and drives India towards an AI product nation with a global footprint.
How does one envisage the form and function of ‘Regulation for AI’? In this open house, we have a dialog between technology and legal sides of the approach to explain the significant facets.
In a nutshell, ‘Regulation for AI’ will focus on
what standards the AI models need to adhere to
define a lightweight but foolproof path for getting there for startups as well as the big players
provide an environment which deals with many of the compliance and safety aspects ab initio
define ways to remove hurdles from the innovator’s paths
In contrast, ‘Regulation of AI’ deals with what AI models cannot be and do and the tests and conditions that they have to pass depending on the risk classes that they are placed into. This is akin to certification processes in many fields such as pharma, transportation and so on which impose heavy cost burdens, especially on new innovators. For instance, many pharma companies which develop potentially good drug candidates run out of steam trying to meet the clinical trial conditions. Very often they are unable to find a valid and sizeable sample population to test their products as a part of the mandatory certification process.
The current standards in the new Regulation of AI in the US, EU and so on leave many aspects such as the risk model classification process undefined, leading to regulatory uncertainty. This also works against investment driven innovation and consequent growth of the ecosystem in multiple ways.
The path to value both for the economy and the users, lies in the power of the data being projected into the universe of applications. These applications will be powered by the AI models in addition to other algorithmic engines. The earlier blogs already addressed the need and the way for data to make their way into models.
For the models to exhibit their power, we must make sure they are reliable and used widely. This requires the AI models be accessible and available and most importantly, ‘do no harm’ when they are applied, through mistakes, misuse or malfeasance. In addition to this, humans or their agents must not be allowed to harm the markets and users through monopoly control of the AI models. Large scale monopolistic control of these models which have global use and relevance can lead to situations which are beyond national or international legislation to control or curb.
In the DEPA model, this benign, and in most ways, benevolent environment is created by a concinnous combination of technology and legal principles. Having analyzed the technological aspects of data privacy in the earlier blogs in this chain, here we will talk about the regulations implemented via a Self-Regulatory Organization – the SRO.
Though not fully fleshed out, the SRO provides functions such as registration and roles to participants such as TDP (Training Data Provider), TDC (Training Data Consumer) and CCRP (Confidential Clean Room Provider). Many of these functions have been implemented in part to support the tech stack that we have released with respect to the CCR (Ref: DEPA Open House #1). This tech stack currently supports registration and allows the interactions between participants to be mediated via electronic contracts (the technological counterpart of legal contracts).
The technology that validates the models through pre-deployment analysis based on complex adaptive system models is under development and is based on diverse research efforts across the world. This technology is designed for measuring the positive and negative impact of use of these models on societies at small and large scale and in short and long timescales.
‘Complex adaptive system models’ are dynamic models which can capture agents with their state information and the multiple feedback loops which determine the changes in the system at different scales, sometimes simultaneously. The large number of components and the many kinds of feedback loops with their dynamic nature are what make these models complex and adaptive. These models, while still in their infancy in many ways, are critical to the question of understanding the AI models’ impact on societies.
The SRO guides and supports the ecosystem players in building and deploying their models in a safe and secure way with lightweight regulatory ceilings so that large product companies in many fields like finance, healthcare, and education can grow and reach a happy consumer base. This is key to growing the ecosystem and connecting it to other parts of the India stack.
We envisage leveraging the current legal system in terms of the different Acts (DPDP, IT Act, Copyright etc.) and models of Data Protection through CDO ( Chief Data Office) and CGO ( Grievance Office) in companies in India in defining the SRO’s role and features further.
The regulatory model also looks at the question of data ownership and copyright issues, especially in the context of Generative AI. We require large foundation models independent of the ‘Big Tech’ to fight potential monopolies. These models should be reflective of the local diversity to serve as reliable engines in the context of India. We need these models built and deployed locally, to be able to play a role as a product nation without being subverted or subjugated in our cyberspace strategies.
To light up the AI sky with these many ‘fireflies’ in different parts of India, infrastructure for compute as well as market access is needed. The SRO creates policies that are not restrictive or protective but promotes participation and value realization. The data players, compute providers, market creators and users need to be able to play with each other in a safe space. Sufficient protection of copyright and creative invention will be provided via existing IP law to incentivize participation while not restricting to the point of killing innovation – this is the balance that the regulatory framework of SRO strives to reach.
Drawing upon ideas of risk-based categorization of models (such as in the EU AI Act) and regulatory models (including punitive and compensatory measures) proportional to them, the models in India Stack will be easily compatible with international standards, as well as a universal or global standard, should an organization such as a UN agency define it. This makes global market reach of AI models and products built in India, an easier target to achieve.
We conjecture that these different aspects of DEPA will release the data from its silos. AI models will proliferate with multiple players profiting from infrastructure, model building, and exporting them to the world. Many applications will be built which will be used both in India (as part of the India Stack) and the world. It is through these models and applications that the latent potential and knowledge in the vast stores of data in India will be realized.
This is the 2nd blog in a series of blogs describing and signifying the importance of DPI for AI, a privacy-preserving techno-legal framework for AI data collaboration. Readers are encouraged to first go over the 1st blog for better understanding and continuity.
What is unique about the techno-legal framework in DPI for AI is that it allows for data collaboration without compromising on data privacy. Now let’s put this in perspective of Indian enterprises and users. This framework can potentially revolutionize the entire ecosystem to slingshot India towards an AI product nation where we are not just using AI models developed within India but exporting the same. What is the biggest roadblock in this dream? In this open house (https://bit.ly/DEPA-2), we make a case that privileged access to data from Indian contexts is not only necessary to develop AI-based systems that are much more relatable to Indians but in fact, gives Indian innovators a distinct advantage over much larger and better funded big tech companies from the west.
Let’s get started. Clearly, there is a race to build larger and larger AI models these days trained on as much training data as possible. Most training data used in the models is publicly available on the web. Given that Indian enterprises are quite behind in this race, it is unlikely that we will catch up by simply following their footsteps. But what many folks outside of AI research circles often miss is that there has been credible research that shows that access to even relatively small amounts of contextual data can drastically reduce the data and compute requirements to achieve the same level of performance.
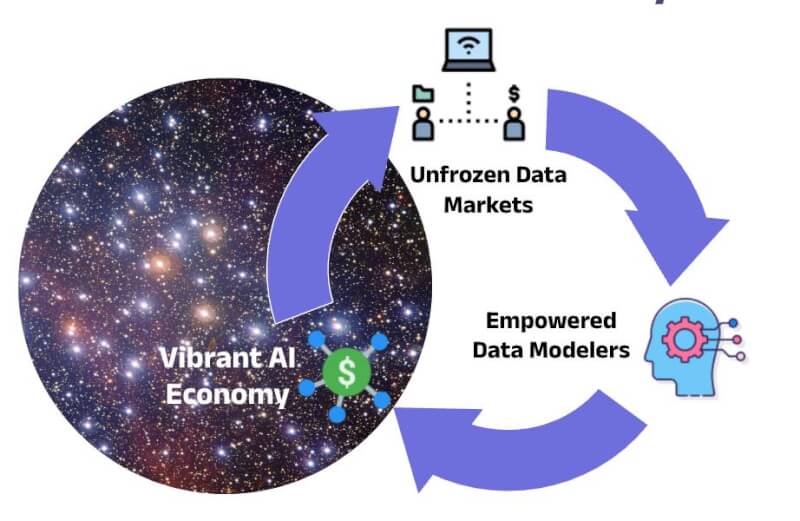
This sounds great, right, but (there is always a but!) much of this Indian context data is not in one place and is hidden behind numerous government and corporate walls. What makes the situation worse is most of these data silos are enterprises of traditional nature and are not the typical centers of innovation, at least for modern technologies like AI. This is a fertile ground for DPI for AI. The three core concepts of DPI for AI ensure that this data sitting in silos can be seamlessly (thanks to digital contracts) and democratically shared with innovators around India in a privacy-preserving manner (thanks to differential privacy). The innovators also do not need to worry one bit about the confidentiality of their IP (thanks to confidential computing). The techno-legal framework makes it super easy for anyone to abide by the privacy regulations without sweat. This will keep them safe from future litigations as long as they follow easy-to-follow guidelines provided in the framework. This is what we refer to as the unfreezing of data markets in this Open House. This unfreezing is critical for our innovators to get easy access to contextual data to give them a much-needed leg up against the Western onslaught in the field of AI. This is India’s moment to leapfrog in the field of AI as we have done in so many domains (payments, identity, internet, etc.). Given the enormity of the goal and the need to get it right, we seek participation from folks from varied expertise and backgrounds. Please share your feedback here
In the last decade, we’ve seen an extraordinary explosion in the volume of data that we, as a species, generate. The possibilities that this data-driven era unlocks are mind-boggling. Large language models, trained on vast datasets, are already capable of performing a wide array of tasks, from text completion to image generation and understanding. The potential applications of AI, especially for societal problems, are limitless. However, lurking in the shadows are significant concerns such as security and privacy, abuse and mis-information, fairness and bias.
These concerns have led to stringent data protection laws worldwide, such as the European Union’s General Data Protection Regulation (GDPR) and California’s Consumer Privacy Act (CCPA), and the European AI Act. India has recently joined this global privacy protection movement with the Data Protection and Privacy Act of 2023 (DPDP Act). These laws emphasize the importance of individuals’ right to privacy and the need for real-time, granular, and specific consent when sharing personal data.
In parallel with privacy laws, India has also adopted a techno-legal approach for data sharing, led by the Data Empowerment and Protection Architecture (DEPA). This new-age digital infrastructure introduces a streamlined and compliant approach to consent-driven data sharing.
Today, we are taking the next step in this journey by extending DEPA to support training of AI models in accordance with responsible AI principles. This new digital public infrastructure, which we call DEPA for Training, is designed to address critical scenarios such as detecting fraud using datasets from multiple banks, helping with tracking and diagnosis of diseases, all without compromising the privacy of data principals.
DEPA for Training is founded on three core concepts, digital contracts, confidential clean rooms, and differential privacy. Digital contracts backed by transparent contract services make it simpler for organizations to share datasets and collaborate by recording data sharing agreements transparently. Confidential clean rooms ensure data security and privacy by processing datasets and training models in hardware protected secure environments. Differential privacy further fortifies this approach, allowing AI models to learn from data without risking individuals’ privacy. You can find more details how these concepts come together to create an open and fair ecosystem at https://depa.world.
DEPA for Training represents the first step towards a more responsible and secure AI landscape, where data privacy and technological advancement can thrive side by side. We believe that collaboration and feedback from experts, stakeholders, and the wider community are essential in shaping the future of this approach. Please share your feedback here