This blog is an invitation to advance public discourse on techno-legal regulation of artificial intelligence (AI). It builds on an article by Rahul Matthan (15 January 2025), in which he raised reservations about applying techno-legal regulation to AI governance and expressed concerns about the practicability of techno-legal artefacts-particularly their ability to establish liability chains among ecosystem actors-as a tool for enforcing good behaviour and ensuring accountability for AI harms. Through a Q&A format, this blog addresses those reservations and concerns directly, while explaining why techno-legal regulation is not only feasible but also the only practicable and scalable way to regulate AI effectively
Techno-legal regulation isn’t a monolithic concept, it can assume multiple implementations for different problems. DEPA Training embeds privacy and sovereignty requirements directly into AI training pipelines through confidential clean rooms and differential privacy. DEPA Inference creates consent-based data sharing. The proposed AI Chain architecture would establish liability tracking through distributed ledgers. Each solves a different problem using the same core principle: making regulatory compliance systematically enforced rather than legally suggested.
The confusion arises because people conflate these distinct systems. DEPA Training ensures AI models can do data collaboration. Privacy budgets will prevent individual contributions from being traced. DEPA Inference ensures PII based data can’t be accessed without consent because the cryptographic handshake fails without a valid consent artifact. AI Chain would ensure accountability can’t be avoided because every inference generates a log trace. Three different problems, three different techno-legal solutions, one underlying philosophy: architecture enforces what law requires.
Moreover, tools don’t meet the bar of techno-legal: that is precisely why one would want to craft techno-legal docs to accept technology substrates as keys ideas which are accepted and acknowledged as such to be mechanisable to meet certain key properties and invariants (in the real world). Tools are just instances of realising these mechanisable properties/invariants. For instance — can policy be put as attestable and executable code — why not? Policy is a set of unambiguous rules and so long as they are unambiguous and computable, they are automatable. If exceptions to the rule exist then they must also be documented.
There is a general worry that introducing identities into AI systems will erode privacy. From a computer-systems standpoint, that conclusion doesn’t follow. What matters is how identifiers are created and managed and what is recorded. With pairwise (service-scoped) identifiers, selective disclosure, and tamper-evident logging of metadata (not payloads), systems can offer accountability and simultaneously uphold Privacy by Design (PbD). These are not speculative ideas: the web and major identity programs already run variants at scale.
OpenID Connect has long supported pairwise subject identifiers, which purposely give each relying party a different, opaque value, curbing cross-service linkability. Aadhaar’s Virtual ID (VID) and UID tokenization make the same design choice in India: a revocable, tokenized identifier is presented instead of the Aadhaar number, and per-agency tokens prevent easy correlation across services while remaining auditable. In both cases, the principle is the same—identity is scoped to a context.
On the web, the W3C Verifiable Credentials (VC) 2.0 model and cryptographic suites such as BBS+ allow a holder to prove only the claims that are necessary (for example, “over 18”) while withholding the rest; the SD-JWT work in the IETF ecosystem supports similar selective-disclosure for JWTs (JSON Web Tokens). The direction of travel — both in standards and deployments — is to treat “need-to-know” as a first-class property.
Every time a browser trusts a public TLS certificate, it relies on Certificate Transparency (CT) — append-only Merkle-tree logs with efficient inclusion and consistency proofs—to keep Certificate Authorities honest. Chrome and Apple have required CT for certificates issued after 2018. Therein lies a lesson for AI: append-only, publicly auditable logs are one mature way to record event receipts without exposing content.
PbD’s “positive-sum” stance is compatible with a metadata-only accountability layer. Instead of retaining prompts, outputs, or personal payloads, systems can emit signed, append-only receipts that capture who/what/which/when: a scoped user identifier, model and dataset versions, operation type (e.g., generate/transform/moderate), timestamp, and the responsible (but not necessarily trusted) operator or process. Auditors later verify that events occurred and in which order via Merkle proofs; when a lawful process requires more detail, selective-disclosure credentials release the minimum necessary information. This is the same architectural separation that keeps web PKI and identity wallets both auditable and privacy-preserving.
When we track things securely, we do not create a surveillance state. We create a modelable, measurable, manageable state. When the tracking data is misused by parties – parties in power or parties with power to access the data, bypassing access checks – then they have the ability to create a surveillance state or cause damage. DEPA liability chains are designed to establish the connections between different parts of the data economy ecosystem, but using strong cryptographic techniques to detect and protect against unauthorised access.
Traceability and agency/activity chains are needed to construct the data economy ecosystem robustly.
India needs techno-legal regulation because we can’t afford not to have it. We don’t have thousands of judges to adjudicate AI harm. We don’t have armies of auditors to verify compliance. We have scale challenges the West doesn’t face, governing AI for 1.4 billion people requires architectural enforcement. We need to protect our people and enable our innovators.
The question isn’t whether we need techno-legal regulation, it’s whether we’re honest about what happens without it. Without DEPA Training’s cryptographic enforcement, AI systems will train on unauthorized data because detection is impossible at scale. Without immutable audit trails, companies will claim compliance while violating every principle because verification requires resources we don’t have. Without architectural enforcement, the most vulnerable Indians, those who can’t afford lawyers, don’t understand technology, can’t navigate bureaucracy, will be harmed first and most.
AI space is an unknown space. To define legal regulation in a space we need to be able to enumerate ( exhaustively if possible) all the failure modes in the system and then frame the regulations to prevent, to detect, to curtail impact, to correct after the event etc. When we know the details one can compute the legal implications and consequences and define a legal regulation ( 80 percent) supported by technology ( 20 percent). When we are dealing with an unknown space, unknown in the sense that the failure modes are not enumerable, then we can do techno-legal regulation in an evolutionary manner ( even more so when the activity is distributed in space and time and occurring with a high frequency ). Here we start with a base implementation and evolve it based on the discovery of failure modes. We can argue that such an evolutionary approach to creating regulation that not only protects but also fosters growth needs to be implemented on a technology substrate (80 percent tech 20 percent human). Otherwise the evolution will be very slow and the regulation will be out of sync with market needs.
True, current technologies may not be able to solve use limitation and/or data minimisation in the world of AI ex-ante, however, the question should be can we construct testable tech mechanisms to check violations of these requirements ex-post. I believe that is certainly possible — challenging but doable.
DEPA does solve for this indirectly. Retention restrictions, usage limitation, data minimization, all require deep understanding of how and where data is being used. DEPA chains track and trace and provide this information which will enable the DEPA framework itself to implement and enforce these and other constraints and conditions on data use. Without a technology framework to do this, it is likely that there will be many more violations of these kinds of conditions without coming to light. The more complex the regulations get, the more technologically advanced and evolutionary the substrate needs to be.
We’re not encoding Platonic ideals of fairness, we’re implementing specific, measurable requirements that regulators and courts have already defined. DEPA Training’s architecture can use techno-legal solutions to enforce fairness principles, it may work like this: when a dataset enters the clean room, the system automatically computes demographic distributions and compares them against regulatory baselines. If biases are detected appropriate remedial measures are effected.
We welcome feedback and suggestions from all stakeholders at [email protected]
Please note: The blog post is authored by our volunteers, Sunu Engineer, Subodh Sharma, Raj Shekhar and Harshit Kacholiya
 This can be called creating the functionality.
This can be called creating the functionality.




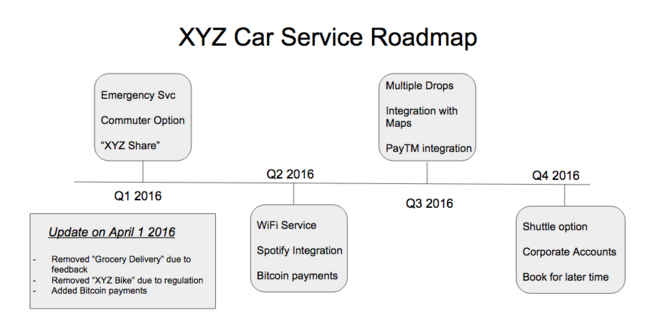 Figure 1 : Example external roadmap for a fictional car ride share company.
Figure 1 : Example external roadmap for a fictional car ride share company. 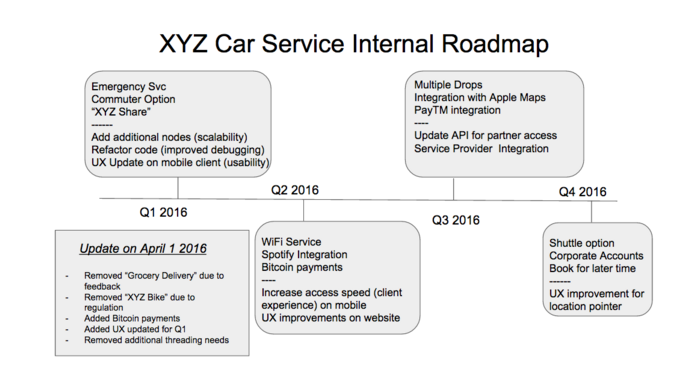

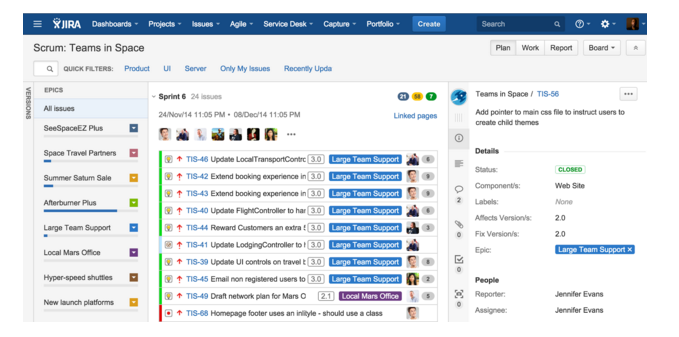 Figure 4: Using JIRA for sprint planning. See
Figure 4: Using JIRA for sprint planning. See  “A great product manager has the brain of an engineer, the heart of a designer, and the speech of a diplomat”
“A great product manager has the brain of an engineer, the heart of a designer, and the speech of a diplomat” Amit emphasised the importance of tracking the product’s viral coefficient which is the number of additional members every new member brings. It should be greater than 1 for the product to become viral.
Amit emphasised the importance of tracking the product’s viral coefficient which is the number of additional members every new member brings. It should be greater than 1 for the product to become viral.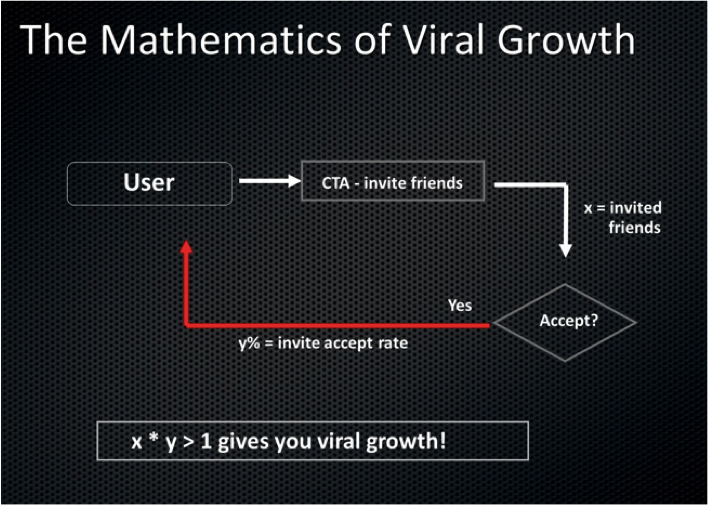
 To give you a taste of how things play out in the real world:
To give you a taste of how things play out in the real world:
 Best Practices For Product Development:
Best Practices For Product Development: 
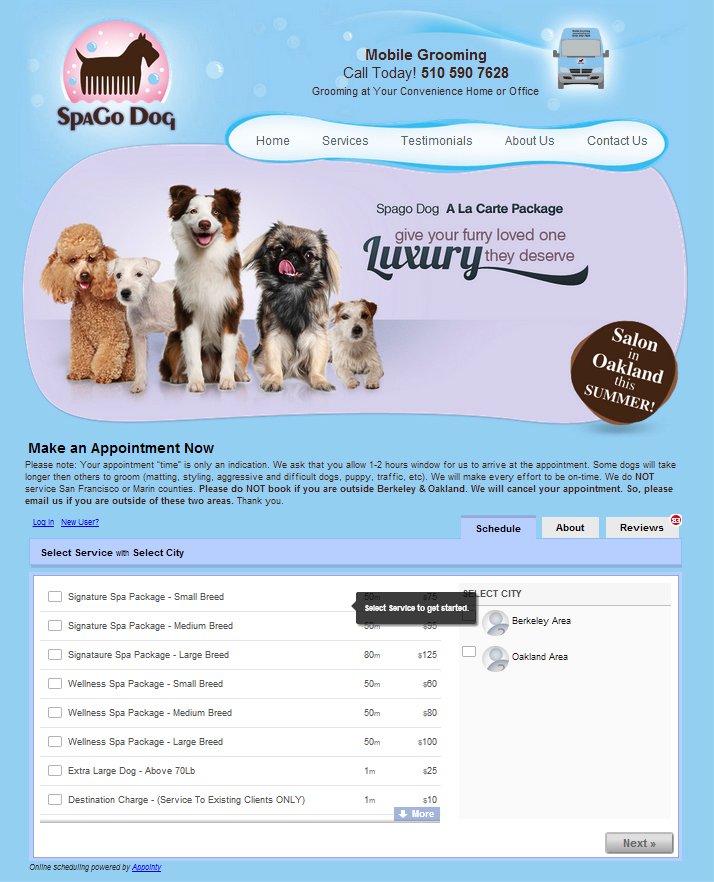
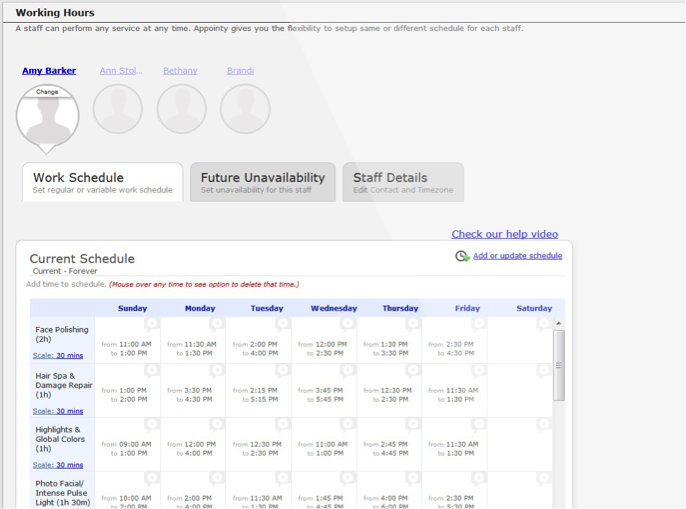
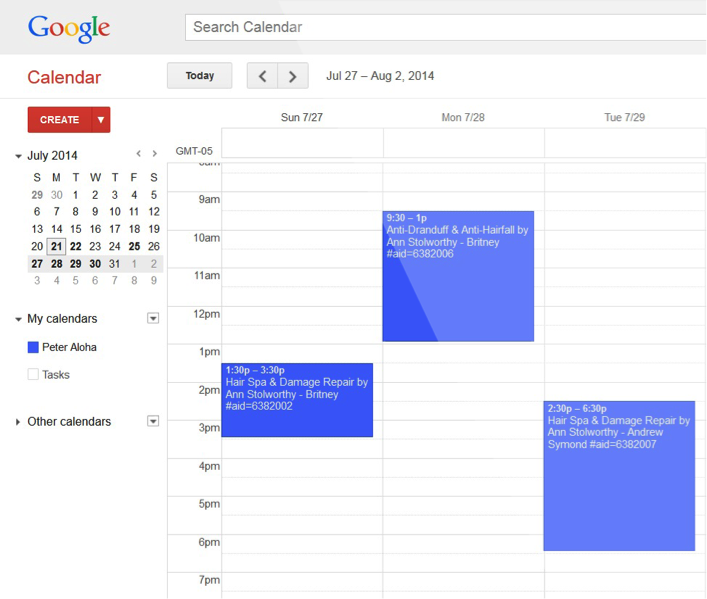

 What interested me in Product Management, after having done multiple roles both on the business and the engineering side, was a desire to understand the big picture and play a pivotal role in deciding the success of a product and it has been my passion and interest ever since.
What interested me in Product Management, after having done multiple roles both on the business and the engineering side, was a desire to understand the big picture and play a pivotal role in deciding the success of a product and it has been my passion and interest ever since.