This is a two part blog series. The following is the first part.
Every day, we generate vast amounts of digital data — withdrawing cash, visiting doctors, ordering groceries, using various mobile apps. These data trails have the potential to streamline services, personalize experiences, and drive breakthroughs in fields from medicine to finance. Yet they also carry risks: unfair profiling, intrusive targeting, and exposure of sensitive personal information.
This presents a fundamental challenge: How can we harness the value of data while preserving individual privacy?
Understanding Privacy
In the age of AI, privacy violations no longer just expose personal information. They erode autonomy and tilt power toward those who control data and algorithms. As AI systems harvest behavioral cues, digital footprints, and social networks, people lose control, not just over their information, but also over how they are profiled and influenced. This enables subtle yet pervasive forms of coercion, from tailored manipulation of choices to algorithmic exclusion from opportunities.
At scale, such surveillance dynamics erode trust and weaken democratic agency. In this era, privacy is not merely about secrecy, it is a precondition for freedom, dignity and meaningful participation in society.
Privacy is often mistaken for confidentiality, but it’s not simply about hiding information. Privacy is the property of not being able to identify individuals from the signals they produce. Confidentiality, on the other hand, is about limiting access to those signals in the first place. To protect privacy and confidentiality while respecting individual autonomy, we need strong control mechanisms that let people decide what data is shared, with whom, for what purpose, and for how long.
And privacy isn’t a one-time setting. Data moves through a lifecycle — it is collected, used, stored, reused, and eventually deleted. These protections must hold at every stage, or they are lost.
The Mechanics of Consent
Today, consent remains the most common mechanism for privacy — the basic control primitive intended to let people decide how their data is collected, shared, and used. The concept of consent actually predates the digital era — it began in a paper-based world, where signatures and written permissions served as the primary means of authorizing data use.
It is important to distinguish between two kinds of consent:
- Consent to collect data – allowing an entity to initially gather your data (for example, an app accessing your camera).
- Consent to share data – granting permission for that data to be used or passed on for a specific purpose (for example, a bank sharing your salary details with a loan underwriter).
Our focus in this article is on consent to share data, since that is where both the greatest privacy challenges and the most meaningful opportunities for value creation lie.
Here is the problem with how consent is currently implemented today. Under frameworks like GDPR, consent has been defined as a very coarse-grained and blunt artifact. The same entity collects your data, gathers your consent, and enforces the rules around its use. For individuals, this typically means an all-or-nothing choice — share everything or nothing at all. And for innovators, it stifles the ability to responsibly explore new uses of data.
India’s Innovation: Unbundling Consent
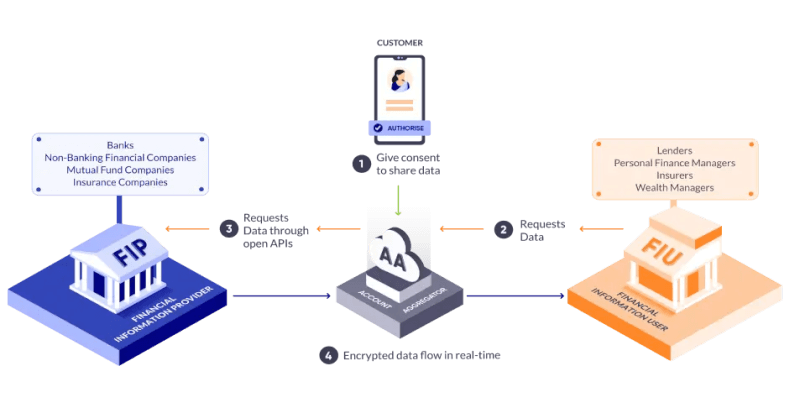
When India designed its Account Aggregator system for financial data sharing, it chose a different path. Consent to share data was unbundled into two parts:
- Collect consent: Managed by trusted intermediaries called Account Aggregators.
- Enforce consent: Managed downstream by Financial Information Users (like banks or wealth advisors), under ecosystem oversight.
https://sahamati.org.in/what-is-account-aggregator/
At the heart of this design lies a set of principles that make consent Open, Revocable, Granular, Auditable, Notifying, and Secure — or ORGANS for short.
The Account Aggregator (AA) framework became the first manifestation of DEPA — the Data Empowerment and Protection Architecture. It is now India’s go-to model for user-consented data sharing between institutions, especially for straightforward data transfers and simple inference tasks.
Where Consent Reaches Its Limits
Consent works well for inferences — one-time decisions like a bank checking your last six months of transactions to approve a loan. Yet, in practice, consent has well-known limits. People are asked to grant permission repeatedly, often through long, opaque terms they don’t fully understand, leading to consent fatigue and a loss of meaningful control.
These limitations become clearer when we move from individual decisions to model training and large-scale analytics, where algorithms learn patterns from millions of records. Seeking or managing consent at that scale is neither practical nor effective.
What’s worse is that models can sometimes memorize sensitive data and inadvertently reveal it later. This highlights the need for new, complementary control primitives that uphold privacy and accountability even when explicit consent isn’t feasible.
Attempts at de-identification — the process of removing or masking identifiers to anonymize data – have significant limitations in practice. Although anonymization is meant to ensure that individuals cannot be re-identified, de-identification techniques are often reversible when datasets are combined with external information. As a result, such approaches offer only weak privacy guarantees, and numerous cases have shown how easily supposedly “anonymous” data can be linked back to individuals.
Privacy-preserving Algorithms: A New Control Primitive for Training and Analytics
To address these limits, a new class of algorithms has emerged under the broad umbrella of Privacy-Enhancing Technologies (PETs). Let us call these privacy-preserving algorithms, to differentiate them from other classes of PETs. They provide a spectrum of technical safeguards that preserve privacy while still enabling useful computation and collaboration on sensitive data.
Among these, Differential Privacy (DP), a mathematical framework for preserving individual privacy in datasets, stands out as a powerful privacy primitive for model training and data analysis.
The key idea: DP adds carefully calibrated noise to queries or model updates so that the results are statistically indistinguishable whether or not any single individual’s data is included. This ensures that nothing specific about an individual can be reliably inferred.
To make this guarantee rigorous, DP introduces the concept of a privacy budget (often represented by the parameters epsilon ε and delta δ):
- Each query or training step “spends” some of this budget.
- With more queries or training epochs, the cumulative privacy loss increases.
- Once the budget is exhausted, no further queries or training is allowed, keeping the risk of re-identification mathematically bounded.
Think of this as a quantitative accounting system for privacy loss. Note, however, that DP comes with a utility tradeoff: adding calibrated noise can reduce model accuracy or data usefulness. Hence, depending on the use-case, the right privacy controls may be achieved through other privacy-preserving algorithms, or a combination thereof.
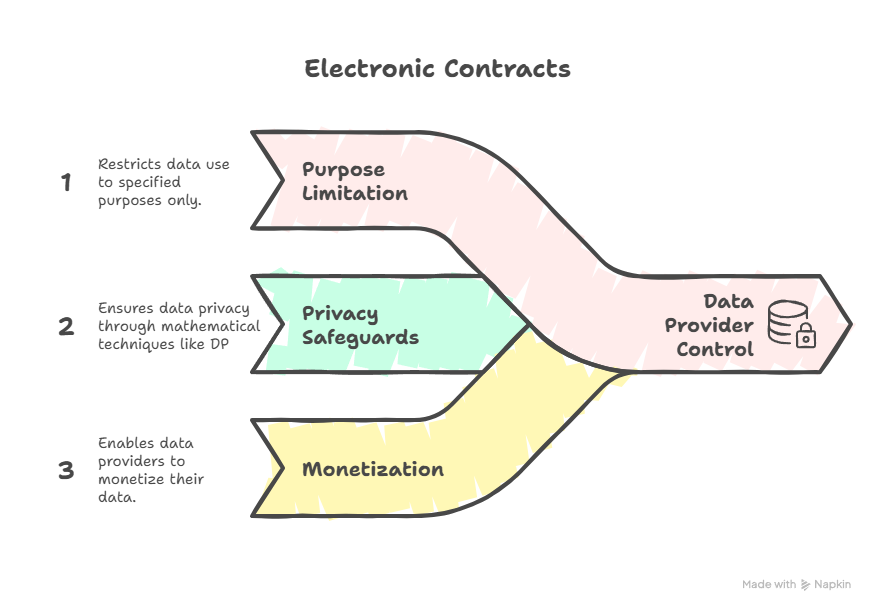
Electronic Contracts: Digitizing Trust
While privacy-preserving computation enables data to be used securely, participants still need clear agreements defining who may use it, for what purpose, or under what conditions. For such collaborations to function effectively, there must be a well-defined and enforceable contractual framework that specifies each party’s rights, obligations, and permissions.
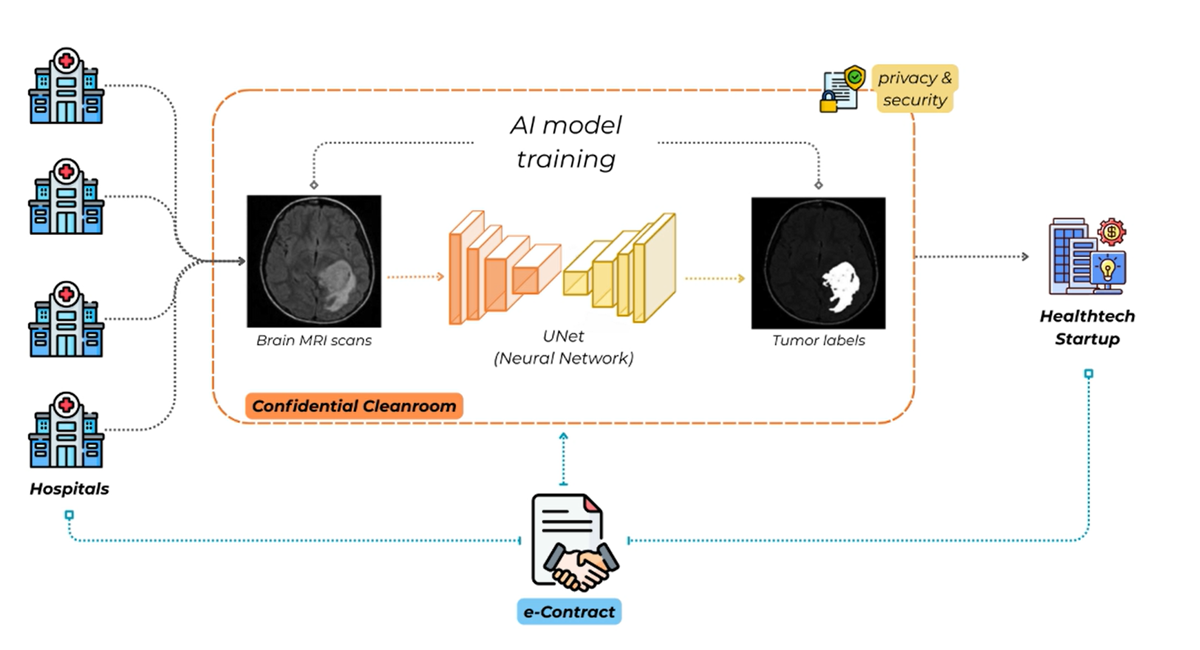
The need for such a framework becomes even more pressing as organizations seek to unlock real value from data. No single dataset is enough; the most meaningful insights arise when information from multiple sources — hospitals, banks, labs, startups, or agencies — can be combined and analyzed responsibly. Yet each participant brings its own rules, contracts, and compliance obligations, creating a patchwork of agreements that are difficult to align.
Traditionally, contracts are legal documents — PDFs or paper agreements — written in human language, interpreted by lawyers, and enforced by institutions. They work well when a few parties are involved, but in modern data collaborations, this model quickly breaks down.
Today, every new collaboration means drafting, signing, and managing a maze of separate legal agreements, often in different formats, scattered across systems, and maintained by hand. With every participant added, the web of contracts grows bulkier, making coordination slow, expensive and error-prone. Every change or dispute requires human intervention and can take weeks or months to resolve.
This contractual friction has long been the viscous drag holding back scalable, compliant data collaboration. Not because trust is missing, but because it is buried under paperwork.
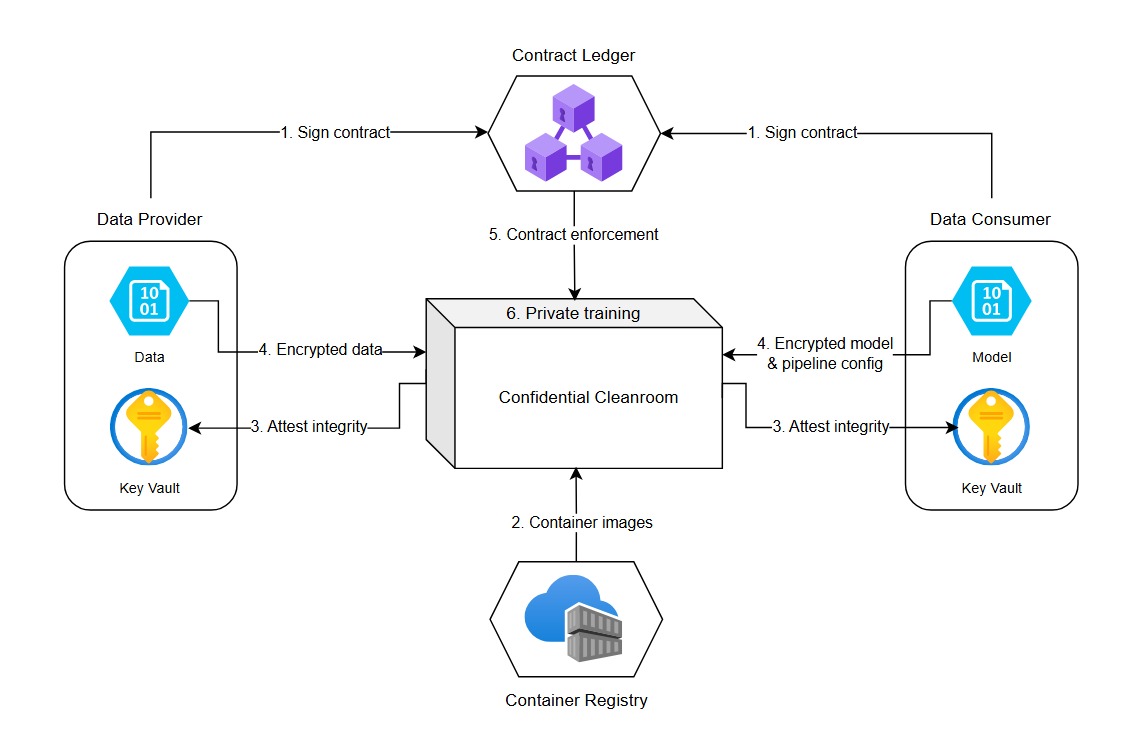
Electronic contracts transform this equation. They are machine-readable, digitally signed, and executable agreements that translate legal promises into enforceable code. Instead of being static documents, they are active digital objects that the DEPA orchestration layer can interpret and act upon — automatically initiating workflows, enforcing permissions, and ensuring compliance.
In effect, electronic contracts bridge law and computation. They enable trust, automation, and accountability at digital speed, replacing manual paperwork with a system that can verify, execute, and audit commitments in real time.
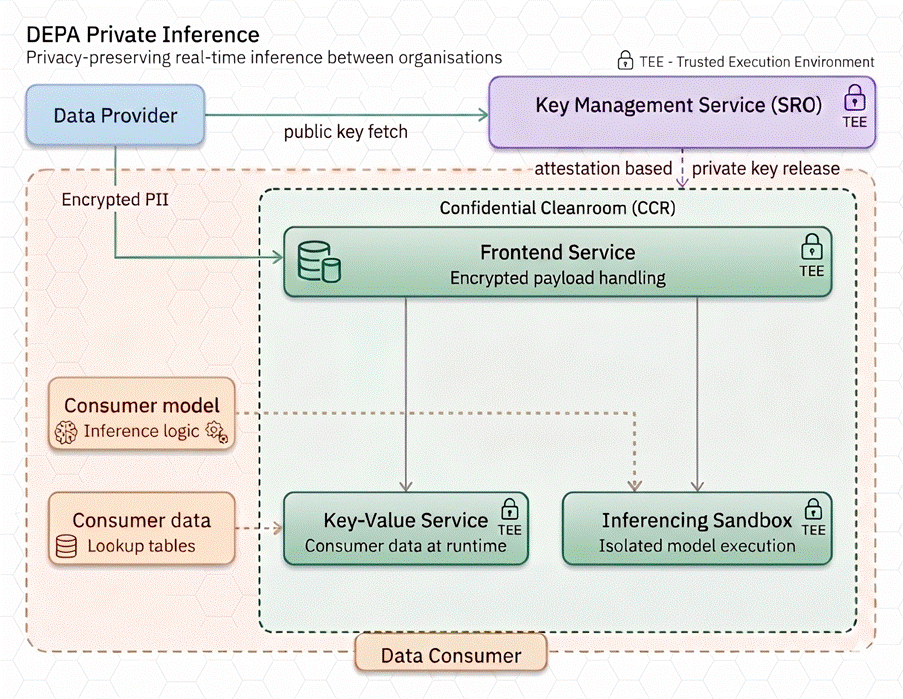
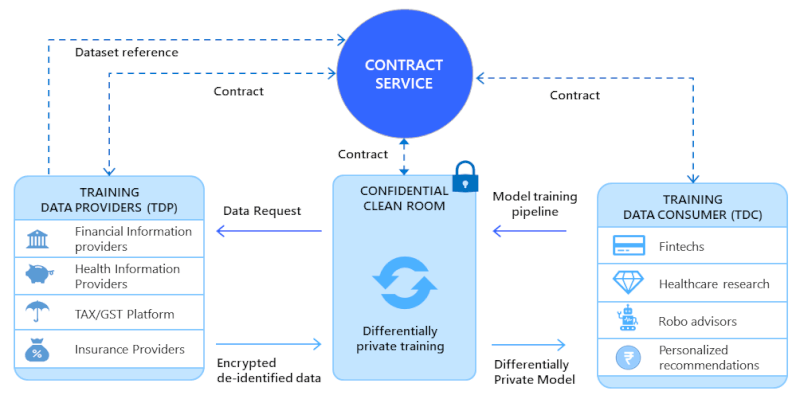
Confidential Clean Rooms (CCR)
To operationalize the above elements, we need infrastructure that embeds privacy and compliance mechanisms by design, while also supporting diverse collaboration modalities — from data analytics and model training to various forms of inference.
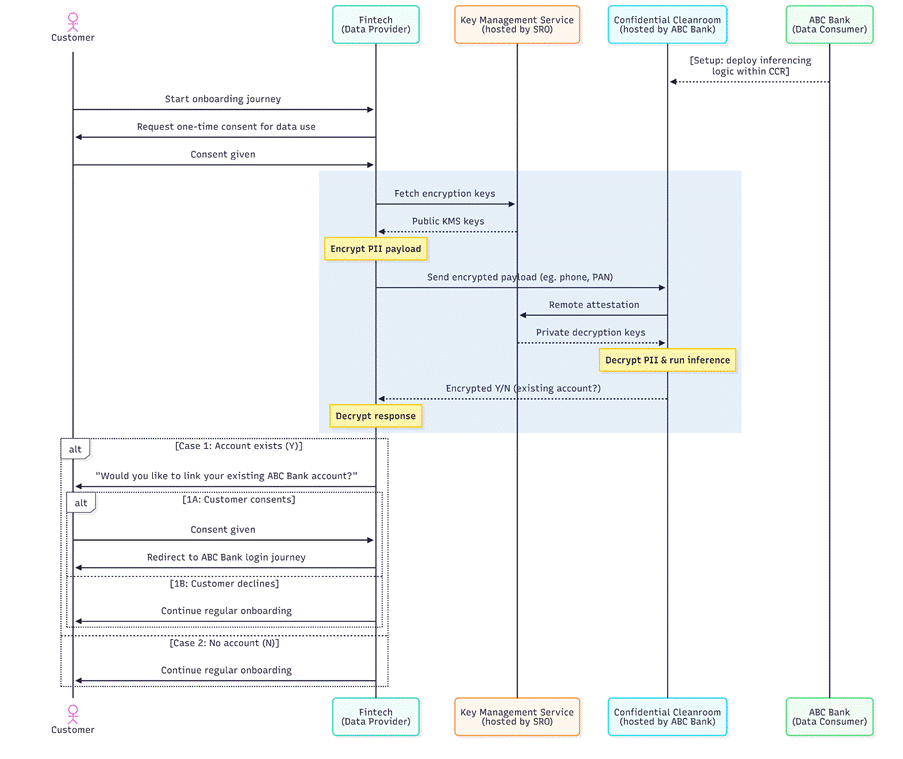
That’s where Confidential Clean Rooms (CCRs) come in. A CCR is a secure computing environment that allows organizations to collaborate on data without ever sharing it in plain form. You can think of it as a locked, monitored laboratory where data from multiple parties can be brought together for analysis — yet no participant, not even the operator of the lab, can peek inside.
At the heart of every CCR is Confidential Computing — a technology that uses Trusted Execution Environments (TEEs) built into modern processors. When data enters a TEE, it is encrypted and isolated from the rest of the system, ensuring that even cloud providers or system administrators cannot access it. Computations run inside this protected enclave, and only verified results can leave. Each TEE also produces a cryptographic attestation, a proof that the computation was executed correctly and under the agreed conditions.
https://depa.world/training/architecture
On their own, CCRs provide secure execution. But when combined with other DEPA primitives..
- Electronic Contracts, which specify who can use what data for what purpose, and
- Privacy-preserving algorithms, which provide mathematical controls about what information can or cannot leak,
..they form a complete privacy-preserving data-sharing stack.
In essence, Confidential Clean Rooms (CCRs) enable confidential, techno-legal, and privacy-preserving computation on data. They make it possible to conduct large-scale data inference, analytics and modelling responsibly, without transferring raw data to any third party, and thereby eliminating the need for consent specifically for data sharing.
But technology alone doesn’t build ecosystems. Who brings this framework to life, abstracting away its complexity for everyday organizations? How might it help us confront our most urgent global challenges — in health, climate and finance? And how could it unlock entirely new kinds of enterprises, fueling a vibrant and responsible data economy for the Intelligence Age?
Data Collabs!
Read Part 2: Privacy in the Age of AI: New Frameworks for Data Collaboration-Part-2
Please note: The blog post is authored by our volunteers, Hari Subramanian and Sarang Galada
For more information, please visit: https://depa.world/