
At iSPIRT, our work on digital public infrastructure for data has consistently focused on a core question: how do we unlock value of data while preserving the rights and trust of individuals? With DEPA (Data Empowerment and Protection Architecture), we established a consent-driven framework that empowers individuals to control how their data is shared for a specific purpose. But there are many business scenarios where consent alone is not sufficient.
Consider a simple scenario: a user consents to share their bank transaction data with multiple lenders for the purpose of credit underwriting. The consent artifact clearly specifies purpose, duration, and data scope. However, once that data is shared with the lenders, the user, and even the bank has no technical visibility into how exactly the data is being used by the lender. Are the lenders only computing a credit score, or also deriving behavioral insights for cross-selling? Are any of the lenders retaining longer than necessary? Is the data being combined with other datasets in ways that go beyond the original intent? These questions are becoming increasingly critical as the use of AI for processing personal data expands to pretty much every sphere from agriculture to finance and healthcare. Consent defines permission, but today there are no technical means to ensure that consent is respected.
DEPA Private Inferencing (part of DEPA 2.0) addresses these concerns. It is a framework that enables high-value scenarios, such as AI inference, while ensuring end-to-end, cryptographically verifiable privacy. DEPA Inferencing introduces a new paradigm: controlled data sharing within clean room environments. It allows data to be shared, but only within secure, purpose-limited and verifiable execution environments. This ensures that users’ consent is enforced while data consumers retain flexibility to run complex computations such as AI models while minimizing compliance costs.
✨ Highlights
👉 Unlocks cross-institution inference without exposing customer data to counterparties
👉 Today: 2 million+ private customer inferences in BFSI sector processed within 2 weeks
👉 Open-source stack available for ecosystem adoption and innovation
Before we dive in, let’s quickly recall what the Data Empowerment and Protection Architecture (DEPA 1.0) really is.
What is DEPA and why does it matter?
India Stack is evolving at population scale, enabling the flow of people (Aadhaar, eKYC, DigiLocker, DigiYatra, etc), money (UPI, OCEN), and information (DEPA and Account Aggregator) through Digital Public Infrastructure (DPI). DEPA is foundational to this third layer. It enables the responsible flow and use of data between individuals and organisations for higher-order economic activity such as cross-sell, analytics, AI model training, and AI inference.
As the name suggests, DEPA rests on two key elements. The first is protection, founded on the bedrock of privacy, consent, accountability and purpose limitation of data. The second is empowerment, democratizing data access and enabling the ecosystem to responsibly innovate with it, whether for training AI models, personalizing products and services, advancing scientific research, and a lot more.
The first instantiation of DEPA is the Account Aggregator (AA) framework, which enables real-time user-consented data sharing between Financial Information Providers (FIPs), entities who hold citizen data, and Financial Information Users (FIUs) or entities that require citizen data to provide a service. That model has been transformative for many use cases and remains foundational to India’s data ecosystem.
What is DEPA Private Inferencing?
DEPA Private Inferencing builds on this foundation by introducing a new layer of control at the point of computation. Instead of transferring data to the consumer’s environment, data is released into a Confidential Clean Room (CCR), a hardware-based secure execution environment where computation happens under strict policy enforcement.
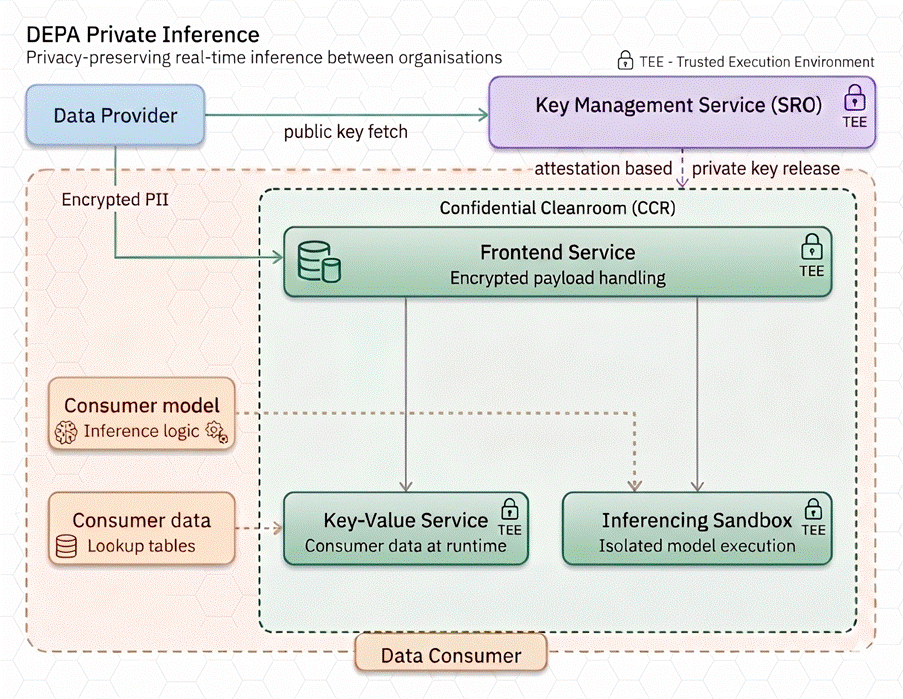
In this model, a data provider (DP) allows access to relevant data to a data consumer (DC), governed by user consent (obtained using AA or otherwise). However, instead of getting raw access to the user’s data, the data consumer (DC) brings their inference logic (for example, a credit risk model) into a confidential clean room. The clean room itself enforces constraints on what data can be accessed, how it can be processed, and what outputs can be generated.
In the first incarnation, DEPA Private Inferencing supports a clean room environment that allows the data to be enriched using the PDC’s own data hosted in the clean room followed by inference using the PDC’s AI model. During this process, the clean room environment ensures that
a) personal data remains encrypted at all times, even during use,
b) inferencing is stateless i.e., the AI model cannot keep any state once the data has been processed, and
c) only the results of inference in a predetermined format are returned to the DP.
Importantly the clean room environment ensures that the DC (or for that matter the cloud provider) cannot observe or tamper with the data or the computation, even if the DC is hosting this computation. This is a subtle but important shift. Data does move, but only into an environment where its usage is technically controlled and purpose limited, even from the DC.
DEPA Private Inferencing provides these assurances using confidential computing, a new set of primitives in modern CPUs (Intel, AMD and ARM) and GPUs (from NVIDIA) which enable creation of cryptographically verifiable isolated execution environments called Trusted Execution Environments (TEEs). TEEs ensure that data remains protected throughout its lifetime, at rest, in transit, and during use. TEEs are now broadly available on most cloud platforms and have been battle-tested in large scale deployments such as WhatsApp and Signal.
If the confidential clean room is where trust is enforced, key management is what ensures that this trust cannot be bypassed. In DEPA Private Inferencing, keys for encrypting data as it is transferred from the DP to the DC are generated and governed within a dedicated, transparent key management service (KMS) operated by Samyog, a neutral not-for-profit self regulated organization (SRO) set up for this purpose. Access to private keys is tightly coupled with attestation. Personal data is encrypted using public keys from the KMS. However, before an inferencing service hosted by a PDC can decrypt data, it must prove, using hardware-backed attestation, that it is running clean room code approved by Samyog inside a genuine TEE. Only after this verification does the KMS release the required decryption key securely wrapped so it can only be used within that specific clean room environment. This creates a separation of control, ensuring that no single participant in the ecosystem can unilaterally access sensitive data.
Similar to the clean room, the KMS itself runs within a tamper-evident, fault-tolerant TEE, with transparency and auditability over key release policies, ensuring even administrators of the KMS cannot access private keys.
DEPA Private Inferencing in action
Our first production deployment of DEPA Private Inferencing connects a leading commercial bank (Data Consumer) with a regulated fintech (Data Provider) to run a simple private inference: Does this fintech customer already hold an account at the bank?
Once the DPDP Act is operationalized, even answering this simple question today will be challenging, because as soon as the customer’s data (e.g., mobile number and PAN card) is exposed to the bank, the bank is responsible for managing the entire consent and data lifecycle. Given banks today typically integrate with dozens of such partners, this creates significant operational and compliance overhead.
With DEPA Private Inferencing, the bank can receive this data in encrypted form inside a CCR pre-loaded with its own customer information, process it, and generate a yes/no response – while proving to the fintech partner that the data was used only for this specific purpose, and that the bank has no technical means to access or retain this data. This builds trust, reduces exposure of raw data, and significantly simplifies partner integrations at scale.
Already, within the first two weeks of deployment, DEPA Private Inferencing has processed over 2 million cross-institution inferences, with a p99 latency of < 100ms, while meeting all of the bank’s security and compliance requirements.
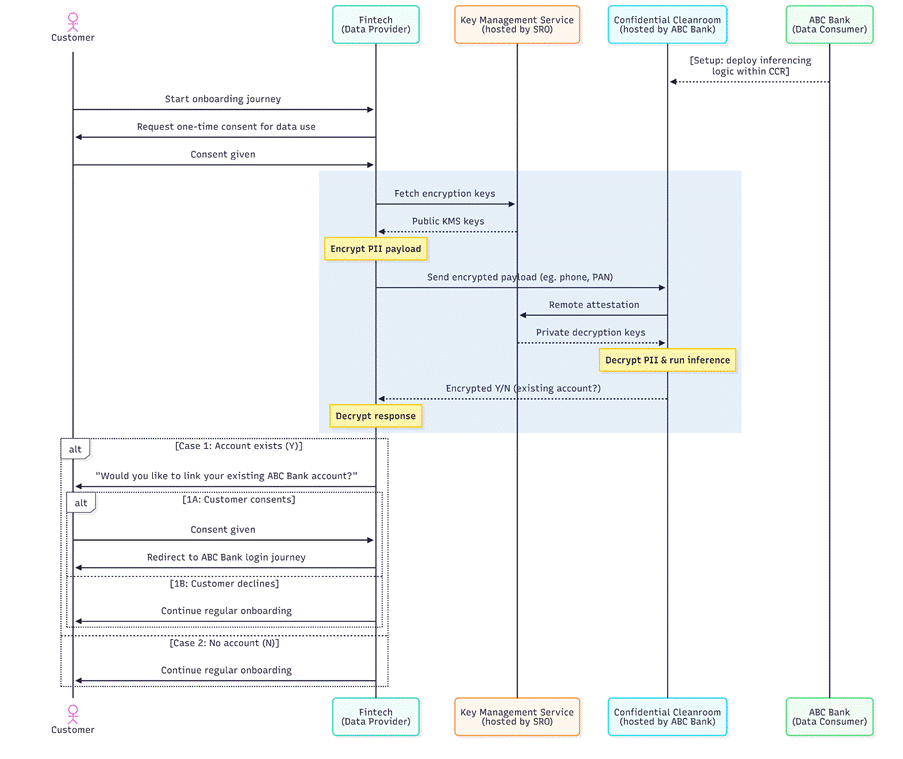
Figure: Example Private Inference flow between a Fintech and a Bank.
A New Primitive for the Data Economy
DEPA Private Inferencing represents a shift from thinking about data as something that must be transferred, to thinking about computation as something that can be safely hosted. The clean room becomes the unit of trust, a neutral, enforceable space where data and algorithms interact under well-defined constraints. As India’s digital public infrastructure continues to evolve, this approach lays the groundwork for a more trustworthy and scalable data economy, one where innovation does not come at the cost of control, and where consent is not just captured, but meaningfully upheld.
Get started
👉 Dive into the code: DEPA‑Inferencing on GitHub 🛠️
👉 Reach out to [email protected] for more info.
👉 Watch the Open House video: YouTube 🎬
👉 Think big: What challenges has data privacy kept off-limits? What data has felt forever inaccessible? With DEPA, those doors may finally open. 💡
Interested in contributing to DEPA? Join our group of no-greed no-glory volunteers! Apply here